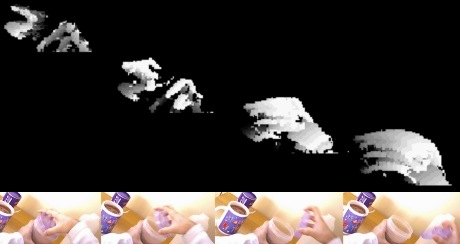
We are developing methods for the estimation of both temporal and spatial visual attention using a head-worn inertial measurement unit (IMU). Aimed at tasks where there is a wearer-object interaction, we estimate the when and the where the wearer is interested in. We evaluate various methods on a new egocentric dataset from 8 volunteers and compare our results with those achievable with a commercial gaze tracker used as ground-truth. Our approach is primarily geared for sensor-minimal EyeWear computing.
From the paper:
Teesid Leelasawassuk, Dima Damen, Walterio W Mayol-Cuevas, Estimating Visual Attention from a Head Mounted IMU. ISWC ’15 Proceedings of the 2015 ACM International Symposium on Wearable Computers. ISBN 978-1-4503-3578-2, pp. 147–150. September 2015.
http://www.cs.bris.ac.uk/Publications/Papers/2001754.pdf
http://dl.acm.org/citation.cfm?id=2808394&CFID=548041087&CFTOKEN=31371660