We describe a novel RGBD relocalisation algorithm based on key point matching. It combines two com- ponents. First, a graph matching algorithm which takes into account the pairwise 3-D geometry amongst the key points, giving robust relocalisation. Second, a point selection process which provides an even distribution of the ‘most matchable’ points across the scene based on non-maximum suppression within voxels of a volumetric grid. This ensures a bounded set of matchable key points which enables tractable and scalable graph matching at frame rate. We present evaluations using a public dataset and our own more difficult dataset containing large pose changes, fast motion and non-stationary objects. It is shown that the method significantly out performs state-of- the-art methods.
Tag: A.Calway
Towards Robust Real-time Visual SLAM
Our project investigates how to improve feature matching within a single camera Real-time Visual SLAM system. SLAM stands for Simultaneous Localisation and Mapping, when a camera position is estimated simultaneously with sparse point-wise representation of a surrounding environment. The camera is hand-held in our case, hence it is important to maintain camera track during or quickly recover after unpredicted and erratic motions. The range of scenarios we would like to deal with includes severe shake, partial or total occlusion and camera kidnapping.
One of the directions of our research is an adaptation of distinctive but in the same time robust image feature descriptors. These descriptors are the final stage of the Scale Invariant Feature Transform (SIFT). This descriptor forms a vector which describes a distribution of local image gradients through specially positioned orientation histograms. Such representation was inspired by advances in understanding the human vision system. In our implementation a scale selection is stochastically guided by the estimates from the SLAM filter. This allows to omit a relatively expensive scale invariant detector of the SIFT scheme.
When the camera is kidnapped or unable to perform any reliable measurement a special relocalisation mode kicks in. It attempts to find a new correct camera position by performing many-to-many feature search and use robust geometry verification procedure to ensure that a pose and found set of matches are in consensus. We investigate a way of speeding up the feature search by splitting the search space based on feature appearances.
The software based on our findings is incorporated into the Real-time Visual SLAM system which is used extensively within the Visual Information Laboratory.
ViewNet
Context enhanced networked services by fusing mobile vision and location
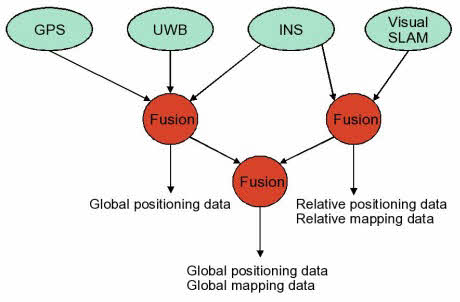
ViewNet is a 1.5M GBP project jointly funded by the UK Technology Strategy Board, the EPSRC and industrial partners. The aim is to develop the next generation of distributed localisation and user-assisted mapping systems, based on the fusion of multiple sensing technologies, including visual SLAM, inertial devices, UWB and GPS.
The target application is the rapid mapping and visualisation of previously unseen environments. It is a multidisciplinary collaboration between the University and a consortium of market leading technology companies and government agencies led by 3C Research. The project is being led by Andrew Calway and Walterio Mayol-Cuevas from the Computer Vision Group and Angela Doufexi and Mark Beach from the Centre for Communications Research in Electrical and Electronic Engineering.
Visual SLAM
 Simultaneous localisation and mapping (SLAM) is the problem of determining the position of an entity (localisation), such as a robot, whilst at the same time determining the structure of the surrounding environment (mapping). This has been a major topic of research for many years in Robotics, where it is a central challenge in facilitating navigation in previously unseen environments. Recently, there has been a great deal of interest in doing SLAM with a single camera, enabling the 6-D pose of a moving camera to be tracked whilst simultaneously determining structure in terms of a depth map. This has been dubbed ‘monocular SLAM’ and several systems now exists which are capable of running in real-time, giving the potential for a highly portable and cheap location sensor.
Simultaneous localisation and mapping (SLAM) is the problem of determining the position of an entity (localisation), such as a robot, whilst at the same time determining the structure of the surrounding environment (mapping). This has been a major topic of research for many years in Robotics, where it is a central challenge in facilitating navigation in previously unseen environments. Recently, there has been a great deal of interest in doing SLAM with a single camera, enabling the 6-D pose of a moving camera to be tracked whilst simultaneously determining structure in terms of a depth map. This has been dubbed ‘monocular SLAM’ and several systems now exists which are capable of running in real-time, giving the potential for a highly portable and cheap location sensor.
We have the following projects running on real-time visual SLAM:
- Robust feature matching for visual SLAM: Matching image features reliably from frame to frame is a central component in visual SLAM. This project is looking at designing new techniques to achieve more robust operation by utilising image descriptors and making use of the estimated camera pose to achieve matching which has greater robustness to changes in camera viewpoint.
- Extracting higher-order structure in visual SLAM. Previous visual SLAM algorithms are based on mapping the depth of sparse points in the scene. This project is looking at expanding the SLAM framework to allow the mapping of higher-order structure, such as planes and 3-D edges, hence producing more useful representations of the surrounding environment.
Our SLAM system is also the central component in the ViewNet project.
You can view an introduction to visual SLAM – slides from the BMVC Tutorial on visual SLAM given by Andrew Calway, Andrew Davidson and Walterio Mayol-Cuevas.
Place Recognition From Disparate Views
Visual place recognition methods which use image matching techniques have shown success in recent years, however their reliance on local features restricts their use to images which are visually similar and which overlap in viewpoint. We suggest that a semantic approach to the problem would provide a more meaningful relationship between views of a place and so allow recognition when views are disparate and database coverage is sparse. As initial work towards this goal we present a system which uses detected objects as the basic feature and demonstrate promising ability to recognise places from arbitrary viewpoints. We build a 2D place model of object positions and extract features which characterise a pair of models. We then use distributions learned from training examples to compute the probability that the pair depict the same place and also an estimate of the relative pose of the cameras. Results on a dataset of 40 urban locations show good recognition performance and pose estimation, even for highly disparate views.

Notable Results
To assess the performance of our system, we collected a dataset of 40 locations, each with between 2 and 4 images from widely different viewpoints. Since we are simply learning distributions over comparisons of places, not about the places themselves, we decided to train the system on a subset of the test dataset to maximise use of the data. To verify that the results were not biased, we tried repeatedly training the system on a random 50% subset of the dataset and running the test again. We found that the learned probability distributions were very similar each iteration, and that the recognition performance did not change by more than about 2%.
A place recognition experiment was then performed. Each image from the dataset was compared against every other image to compute the the posterior probability that the images depict the same place. The table below states the performance of our system under several conditions. The “grouped” score is simply the percentage of test images for which an image from the same place was chosen as the most likely match, simulating a place recognition scenario in which we have made a small number of previous observations of each place. It is interesting however to consider a harder case in which, for each test image, there is only a single matching image in the database. The “pairwise” score simulates this situation by removing all but one of the matching images for each test image.
We also observed that some discriminative ability of the system is provided by the different object classes – so a place with objects of class “sign” and “bollard” cannot possibly match with a place containing only “traffic light” objects. Whilst this is a legitimate place recognition scenario, we wanted to observe the discriminative ability of the features alone. Thus, we also tested the system on a “restricted class” subset of the dataset with 30 locations, all of which contained the same two object classes, meaning that almost every image was capable of valid object correspondences with every other image. Clearly this is a harder case, however the table shows that performance was still reasonable.
| Grouped | Pairwise | |
|---|---|---|
| Restricted class dataset | 67.9% | 54.5% |
| Full dataset | 73.1% | 61.8% |
| GIST (Oliva and Torralba, 2001) | 19.2% | 21.4% |
Plane Detection From Single Images
Our work involves the detection of planar structures from single images. This is inspired by human vision – since humans have an impressive ability to understand the content of both the real world and 2D images, without necessarily needing depth or parallax cues. As such, we take a machine learning route, and learn from a large set of images the relationship between image appearance and 3D structure.
There are two main parts to our method: first, plane recognition, which for a given, pre-segmented image region can classify it as being planar or not, and for planar regions estimate their 3D orientation with respect to the camera. This is done by representing the image region with standard image descriptors, within a bag of words framework enhanced with spatial information. These are used as input to a relevance vector machine classifier, to identify planes, and a regression algorithm to estimate orientation.
Second, the above is used for plane detection, where since we do not generally know the location of potentially planar regions in the image, we apply the plane recognition step repeatedly to overlapping segments of the image. These overlapping regions give allow us to calculate an estimate, at each of a set of salient points, whether they are likely to belong to a plane or not, and their likely orientation (by considering all the regions in which they lie). This point-wise local plane estimate is then segmented to give a discrete set of non-planar and oriented planar regions.
We have also shown (work in collaboration with José Martínez-Carranza) how this single-image plane detection can be useful for visual odometry, where by detecting the presence of likely planar structures from on frame while traversing an outdoor urban environment, planar features can be quickly initialised into the map, with a good prior estimate of their orientation. This allows rough 3D maps of the environment, incorporating higher-level structures, to be rapidly built.
Experimental Results
Plane Recognition
We found that the plane recognition algorithm was able to work well in a variety of outdoor scenes. As well as comprehensive cross-validation, we tested the algorithm on a set of images taken from a completely independent area of the city from the location of the test images (where the region of interest has been marked up by hand). Average classification (plane/non-plane) accuracy was 91.6%, and an orientation (normal vector estimation) error of 14.5 degrees. Some example results from this data set are shown here:

The first three show successful plane detection with estimated orientations (green) compared to ground truth (blue); the last two show identification of non-planar regions.
Plane Detection
The full plane detection algorithm, involving finding planes in previously unseen images, and estimating their orientation, was also tested on an independent data set of images. A few example results are shown here:

References
- Visual mapping using learned structural priors (ICRA 2013)
- Detecting planes and estimating their orientation from a single image (BMVC 2012)
- Estimating planar structure in single images by learning from examples (ICPRAM 2012)