Our work involves the detection of planar structures from single images. This is inspired by human vision – since humans have an impressive ability to understand the content of both the real world and 2D images, without necessarily needing depth or parallax cues. As such, we take a machine learning route, and learn from a large set of images the relationship between image appearance and 3D structure.
There are two main parts to our method: first, plane recognition, which for a given, pre-segmented image region can classify it as being planar or not, and for planar regions estimate their 3D orientation with respect to the camera. This is done by representing the image region with standard image descriptors, within a bag of words framework enhanced with spatial information. These are used as input to a relevance vector machine classifier, to identify planes, and a regression algorithm to estimate orientation.
Second, the above is used for plane detection, where since we do not generally know the location of potentially planar regions in the image, we apply the plane recognition step repeatedly to overlapping segments of the image. These overlapping regions give allow us to calculate an estimate, at each of a set of salient points, whether they are likely to belong to a plane or not, and their likely orientation (by considering all the regions in which they lie). This point-wise local plane estimate is then segmented to give a discrete set of non-planar and oriented planar regions.
We have also shown (work in collaboration with José Martínez-Carranza) how this single-image plane detection can be useful for visual odometry, where by detecting the presence of likely planar structures from on frame while traversing an outdoor urban environment, planar features can be quickly initialised into the map, with a good prior estimate of their orientation. This allows rough 3D maps of the environment, incorporating higher-level structures, to be rapidly built.
Experimental Results
Plane Recognition
We found that the plane recognition algorithm was able to work well in a variety of outdoor scenes. As well as comprehensive cross-validation, we tested the algorithm on a set of images taken from a completely independent area of the city from the location of the test images (where the region of interest has been marked up by hand). Average classification (plane/non-plane) accuracy was 91.6%, and an orientation (normal vector estimation) error of 14.5 degrees. Some example results from this data set are shown here:

The first three show successful plane detection with estimated orientations (green) compared to ground truth (blue); the last two show identification of non-planar regions.
Plane Detection
The full plane detection algorithm, involving finding planes in previously unseen images, and estimating their orientation, was also tested on an independent data set of images. A few example results are shown here:

References
- Visual mapping using learned structural priors (ICRA 2013)
- Detecting planes and estimating their orientation from a single image (BMVC 2012)
- Estimating planar structure in single images by learning from examples (ICPRAM 2012)
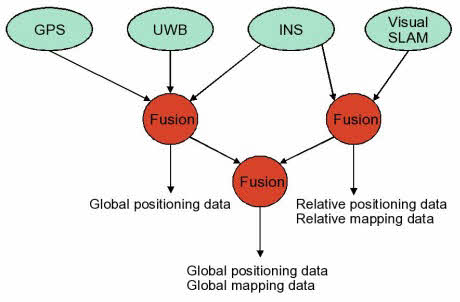

 Simultaneous localisation and mapping (SLAM) is the problem of determining the position of an entity (localisation), such as a robot, whilst at the same time determining the structure of the surrounding environment (mapping). This has been a major topic of research for many years in Robotics, where it is a central challenge in facilitating navigation in previously unseen environments. Recently, there has been a great deal of interest in doing SLAM with a single camera, enabling the 6-D pose of a moving camera to be tracked whilst simultaneously determining structure in terms of a depth map. This has been dubbed ‘monocular SLAM’ and several systems now exists which are capable of running in real-time, giving the potential for a highly portable and cheap location sensor.
Simultaneous localisation and mapping (SLAM) is the problem of determining the position of an entity (localisation), such as a robot, whilst at the same time determining the structure of the surrounding environment (mapping). This has been a major topic of research for many years in Robotics, where it is a central challenge in facilitating navigation in previously unseen environments. Recently, there has been a great deal of interest in doing SLAM with a single camera, enabling the 6-D pose of a moving camera to be tracked whilst simultaneously determining structure in terms of a depth map. This has been dubbed ‘monocular SLAM’ and several systems now exists which are capable of running in real-time, giving the potential for a highly portable and cheap location sensor.
