Richard Vigars
Supervised by: Dave Bull, Andrew Calway
State-of-the-art video coding standards (such as H.264 and H.265) are extremely reliable, and facilitate straightforward rate-quality control. However, certain scenarios remain challenging to the block-based motion and residual coding paradigm. For example, where there is camera motion with respect to highly textured surfaces, particularly if perspective effects are strong, the block-based model produces a large and highly textured residual signal.
To address this problem, we have developed a video codec framework which exploits extrinsic scene knowledge to target higher-order motion models to specific geometrical structures in the scene. We create a textural-geometric model of the scene prior to coding. During coding, we use camera tracking algorithms to track regions of salient scene geometry. Foreground regions are detected and coded by a host codec, such as H.264.
This approach allows us to replace a large volume of the host codec’s bitstream with our own compact motion parameters and side information. Compared to H.264 operating at equivalent quantisation parameters our hybrid codec can achieve bitrate savings of up to 48%.
In breif:
- Applying extrinsic knowledge of the scene in which a video is capture in order to exploit geometrical redundancy in the motion of objects with respect to the camera.
- A perspective motion model is targeted to planar background objects in the scene. This allows large regions of frames in the video sequence to be interpolated from reference frames. These interpolated regions are perceptually acceptable, and as such no residual is required. This translates into large bitrate savings!
- In order to target the perspective motion model to the appropriate regions, tracking techniques similar to those used in augmented reality applications are used.
In terms of theory, this project has turned out to be quite an interesting mix of perceptual video coding and computer vision.
Key algorithms
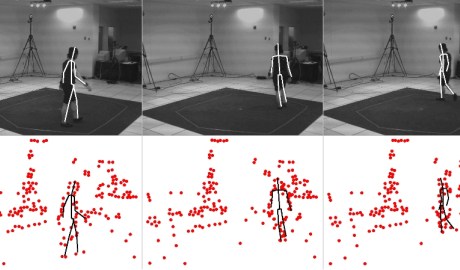
In order to extract a context from the scene a few key operations are performed:

![]()

From left to right these are:
- A set of textural models of key scene planes is extracted using SURF features. These are augmented with polygons giving the approximate locations of other planes in the scene.
- These models are matched to the features in each frame of the video in order to approximately localise the planar structures.
- These approximate locations provide an initialisation for frame-to-frame motion estimation. The use of SURF feature point matching and RANSAC isolates the background motion from that of the foreground.
Foreground segmentation using anisotropic diffusion and morphological operations [1]
The process is depicted in images below:





From left to right:
- Absolute pixel differences between the predicted frame, and the actual frame.
- These difference are then filtered using anisotropic diffusion. This smooth out invisible errors in the texture, while leaving the large errors due to differences in foreground intact.
- A thresholding stage creates a mask.
- The mask is grown into a map.
- Finally, cleaned up using morphological operations.
References
- Krutz et al – Motion-based object segmentation using sprites and anisotropic diffusion, IWIAMIS 2007
Published work
- Context-Based Video Coding – R. Vigars, A. Calway, D. R. Bull; ICIP 2013 (accepted)


 Active contour models, commonly known as snakes, have been widely used for object localisation, shape recovery, and visual tracking due to their natural handling of shape variations. The introduction of the Level Set method into snakes has greatly enhanced their potential in real world applications.
Active contour models, commonly known as snakes, have been widely used for object localisation, shape recovery, and visual tracking due to their natural handling of shape variations. The introduction of the Level Set method into snakes has greatly enhanced their potential in real world applications.