Our project investigates how to improve feature matching within a single camera Real-time Visual SLAM system. SLAM stands for Simultaneous Localisation and Mapping, when a camera position is estimated simultaneously with sparse point-wise representation of a surrounding environment. The camera is hand-held in our case, hence it is important to maintain camera track during or quickly recover after unpredicted and erratic motions. The range of scenarios we would like to deal with includes severe shake, partial or total occlusion and camera kidnapping.
One of the directions of our research is an adaptation of distinctive but in the same time robust image feature descriptors. These descriptors are the final stage of the Scale Invariant Feature Transform (SIFT). This descriptor forms a vector which describes a distribution of local image gradients through specially positioned orientation histograms. Such representation was inspired by advances in understanding the human vision system. In our implementation a scale selection is stochastically guided by the estimates from the SLAM filter. This allows to omit a relatively expensive scale invariant detector of the SIFT scheme.
When the camera is kidnapped or unable to perform any reliable measurement a special relocalisation mode kicks in. It attempts to find a new correct camera position by performing many-to-many feature search and use robust geometry verification procedure to ensure that a pose and found set of matches are in consensus. We investigate a way of speeding up the feature search by splitting the search space based on feature appearances.
The software based on our findings is incorporated into the Real-time Visual SLAM system which is used extensively within the Visual Information Laboratory.

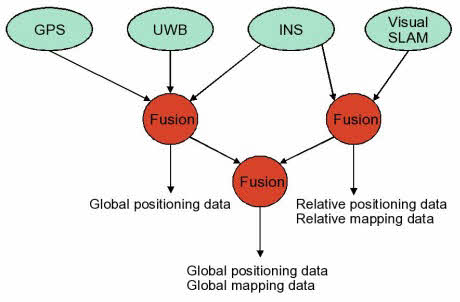

 Simultaneous localisation and mapping (SLAM) is the problem of determining the position of an entity (localisation), such as a robot, whilst at the same time determining the structure of the surrounding environment (mapping). This has been a major topic of research for many years in Robotics, where it is a central challenge in facilitating navigation in previously unseen environments. Recently, there has been a great deal of interest in doing SLAM with a single camera, enabling the 6-D pose of a moving camera to be tracked whilst simultaneously determining structure in terms of a depth map. This has been dubbed ‘monocular SLAM’ and several systems now exists which are capable of running in real-time, giving the potential for a highly portable and cheap location sensor.
Simultaneous localisation and mapping (SLAM) is the problem of determining the position of an entity (localisation), such as a robot, whilst at the same time determining the structure of the surrounding environment (mapping). This has been a major topic of research for many years in Robotics, where it is a central challenge in facilitating navigation in previously unseen environments. Recently, there has been a great deal of interest in doing SLAM with a single camera, enabling the 6-D pose of a moving camera to be tracked whilst simultaneously determining structure in terms of a depth map. This has been dubbed ‘monocular SLAM’ and several systems now exists which are capable of running in real-time, giving the potential for a highly portable and cheap location sensor.





