A novel close-to-sensor computational camera has been designed and developed at the ViLab. ROIs can be captured and processed at 1000fps; the concurrent processing enables low latency sensor control and flexible image processing. With 9DoF motion sensing, the low, size, weight and power form-factor makes it ideally suited for robotics and UAV applications. The modular design allows multiple configurations and output options, easing development of embedded applications. General purpose output can directly interface with external devices such as servos and motors while ethernet offers a conventional image output capability. A binocular system can be configured with self-driven pan/tilt positioning, as an autonomous verging system or as a standard stereo pair. More information can be found here xcamflyer.
Category: Computer Vision
Any project related to Computer Vision
Monitoring Vehicle Occupants
Visual Monitoring of Driver and Passenger Control Panel Interactions
Researchers
Toby Perrett and Prof. Majid Mirmehdi
Overview
Advances in vehicular technology have resulted in more controls being incorporated in cabin designs. We present a system to determine which vehicle occupant is interacting with a control on the centre console when it is activated, enabling the full use of dual-view touchscreens and the removal of duplicate controls. The proposed method relies on a background subtraction algorithm incorporating information from a superpixel segmentation stage. A manifold generated via the diffusion maps process handles the large variation in hand shapes, along with determining which part of the hand interacts with controls for a given gesture. We demonstrate superior results compared to other approaches on a challenging dataset.
Examples
Some example interactions with the dashboard of a Range Rover using near infra-red illumination and a near infra-red pass filter:
Some sample paths through a 3D manifold. The top row of images correspond to a clockwise dial turn. The middle row corresponds to a button press with the index finger, and the bottom shows how finer details such as a thumb extending can be determined:
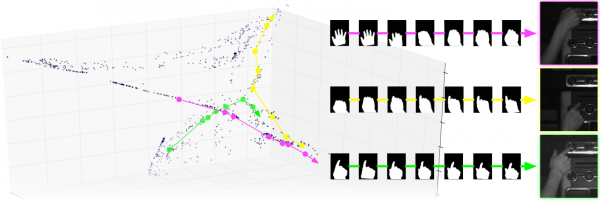
References
This work has been accepted for publication in IEEE Transactions on Intelligent Transportation Systems. It is open access and can be downloaded from here:
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7486959
Remote Pulmonary Function Testing using a Depth Sensor
We propose a remote non-invasive approach to Pulmonary Function Testing using a time-of-flight depth sensor (Microsoft Kinect V2), and correlate our results to clinical standard spirometry results. Given point clouds, we approximate 3D models of the subject’s chest, estimate the volume throughout a sequence and construct volume-time and flow-time curves for two prevalent spirometry tests: Forced Vital Capacity and Slow Vital Capacity. From these, we compute clinical measures, such as FVC, FEV1, VC and IC. We correlate automatically extracted measures with clinical spirometry tests on 40 patients in an outpatient hospital setting. These demonstrate high within-test correlations.
V. Soleimani, M. Mirmehdi, D. Dame, S. Hannuna, M. Camplani, J. Viner and J. Dodd “Remote pulmonary function testing using a depth sensor,” Biomedical Circuits and Systems Conference (BioCAS), 2015 IEEE, Atlanta, GA, 2015, pp. 1-4.
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7348445&isnumber=7348273
RGBD Relocalisation Using Pairwise Geometry and Concise Key Point Sets
We describe a novel RGBD relocalisation algorithm based on key point matching. It combines two com- ponents. First, a graph matching algorithm which takes into account the pairwise 3-D geometry amongst the key points, giving robust relocalisation. Second, a point selection process which provides an even distribution of the ‘most matchable’ points across the scene based on non-maximum suppression within voxels of a volumetric grid. This ensures a bounded set of matchable key points which enables tractable and scalable graph matching at frame rate. We present evaluations using a public dataset and our own more difficult dataset containing large pose changes, fast motion and non-stationary objects. It is shown that the method significantly out performs state-of- the-art methods.
Estimating Visual Attention from a head-mounted IMU
We are developing methods for the estimation of both temporal and spatial visual attention using a head-worn inertial measurement unit (IMU). Aimed at tasks where there is a wearer-object interaction, we estimate the when and the where the wearer is interested in. We evaluate various methods on a new egocentric dataset from 8 volunteers and compare our results with those achievable with a commercial gaze tracker used as ground-truth. Our approach is primarily geared for sensor-minimal EyeWear computing.
From the paper:
Teesid Leelasawassuk, Dima Damen, Walterio W Mayol-Cuevas, Estimating Visual Attention from a Head Mounted IMU. ISWC ’15 Proceedings of the 2015 ACM International Symposium on Wearable Computers. ISBN 978-1-4503-3578-2, pp. 147–150. September 2015.
http://www.cs.bris.ac.uk/Publications/Papers/2001754.pdf
http://dl.acm.org/citation.cfm?id=2808394&CFID=548041087&CFTOKEN=31371660
Home Activity Monitoring Study using Visual and Inertial Sensors
Lili Tao, Tilo Burghardt, Sion Hannuna, Massimo Camplani, Adeline Paiement, Dima Damen, Majid Mirmehdi, Ian Craddock. A Comparative Home Activity Monitoring Study using Visual and Inertial Sensors, 17th International Conference on E-Health Networking, Application and Services (IEEE HealthCom), 2015
Monitoring actions at home can provide essential information for rehabilitation management. This paper presents a comparative study and a dataset for the fully automated, sample-accurate recognition of common home actions in the living room environment using commercial-grade, inexpensive inertial and visual sensors. We investigate the practical home-use of body-worn mobile phone inertial sensors together with an Asus Xmotion RGB-Depth camera to achieve monitoring of daily living scenarios. To test this setup against realistic data, we introduce the challenging SPHERE-H130 action dataset containing 130 sequences of 13 household actions recorded in a home environment. We report automatic recognition results at maximal temporal resolution, which indicate that a vision-based approach outperforms accelerometer provided by two phone-based inertial sensors by an average of 14.85% accuracy for home actions. Further, we report improved accuracy of a vision-based approach over accelerometry on particularly challenging actions as well as when generalising across subjects.
Data collection and processing
For visual data, we simultaneously collect RGB and depth images using the commercial product Asus Xmotion. Motion information can be recovered best from RGB data as it contains rich texture and colour information. Depth information, on the other hand, reveals details of the 3D configuration. We extract and encode both motion and depth features over the area of a bounding box as returned by the human detector and tracker provided by the OpenNI SDK[1]. For collecting inertial data, we opt for subjects to wear two accelerometers mounted at the centre of the waist and the dominant wrist.
The figure below gives an overview of the system.

Figure 1. Experimental setup.
SPHERE-H130 Action Dataset
We introduce the SPHERE-H130 action dataset for human action recognition from RGB-Depth and inertial sensor data captured in a real living environment. The dataset is generated over 10 sessions by 5 subjects containing 13 action categories per session: sit still, stand still, sitting down, standing up, walking, wiping table, dusting, vacuuming, sweeping floor, cleaning stain, picking up, squatting, upper body stretching. Overall, recordings correspond to about 70 minutes of total time captured. Actions were simultaneously captured by the Asus Xmotion RGB-depth camera and the two wireless accelerometers. Colourand depth images were acquired at a rate of 30Hz. The accelerometer data was captured at about 100Hz sampled down to 30Hz, a frequency recognised as optimal for human action recognition.





sitting standing sitting down standing up walking





wiping dusting vacumming sweeping cleaning stain



Picking squatting stretching
Figure 2. Sample videos from the dataset
Results
Vision can be more accurate than Accelerometers. Figure 3 depicts the recognition confusion matrices corresponding to the use of inertial and visual sensors, respectively.
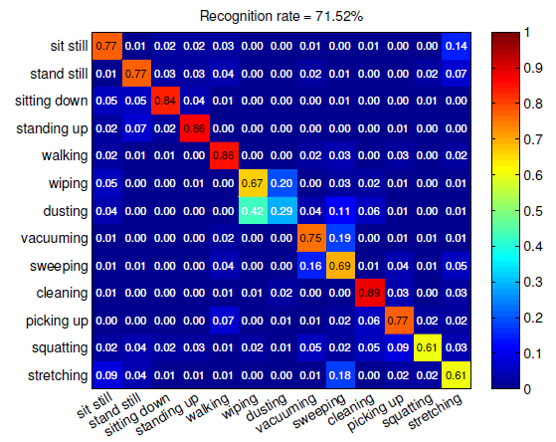
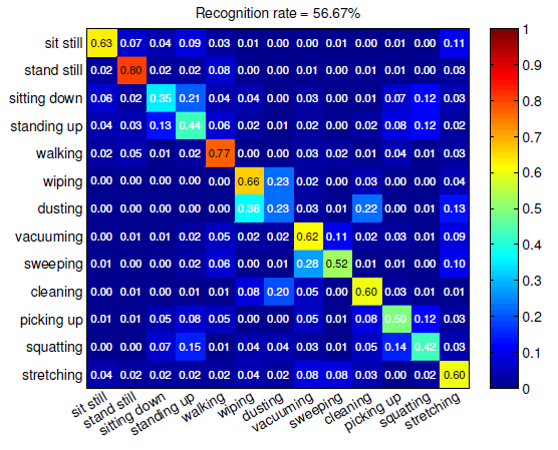
Figure 3. The confusion matrices by (left) visual data and (right) accelerometer data.
Publication and Dataset
The dataset and the proposed method is presented in the following paper:
- Lili Tao, Tilo Burghardt, Sion Hannuna, Massimo Camplani, Adeline Paiement, Dima Damen, Majid Mirmehdi, Ian Craddock. A Comparative Home Activity Monitoring Study using Visual and Inertial Sensors, 17th International Conference on E-Health Networking, Application and Services (IEEE HealthCom), 2015
SPHERE-H130 action dataset can be downloaded here.
References
[1] OpenNI User Guide, OpenNI organization, November 2010. Available: http://www.openni.org/documentation