Ben Daubney, David Gibson, Neill Campbell
Currently we are researching how to extract human pose from a sparse set of moving features. This work is inspired from psychophisical experiments using the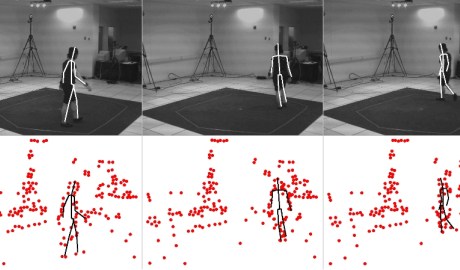 Moving Light Display (MLD), where it has been shown that a small set of moving points attached to the key joints of a person could convey a wealth of information to an observer about the person being viewed, such as their mood or gender. Unlike the typical MLD’s used in the physchophysics community ours are automatically generated by applying a standard feature tracker to a sequence of images.
Moving Light Display (MLD), where it has been shown that a small set of moving points attached to the key joints of a person could convey a wealth of information to an observer about the person being viewed, such as their mood or gender. Unlike the typical MLD’s used in the physchophysics community ours are automatically generated by applying a standard feature tracker to a sequence of images.
The result is a set of features that are far more noisy and unreliable than those tradtionally used. The purpose of this research is to try to better understand how the temporal dimension of a sequence of images can be exploited at a much lower level than currently used to estimate pose.