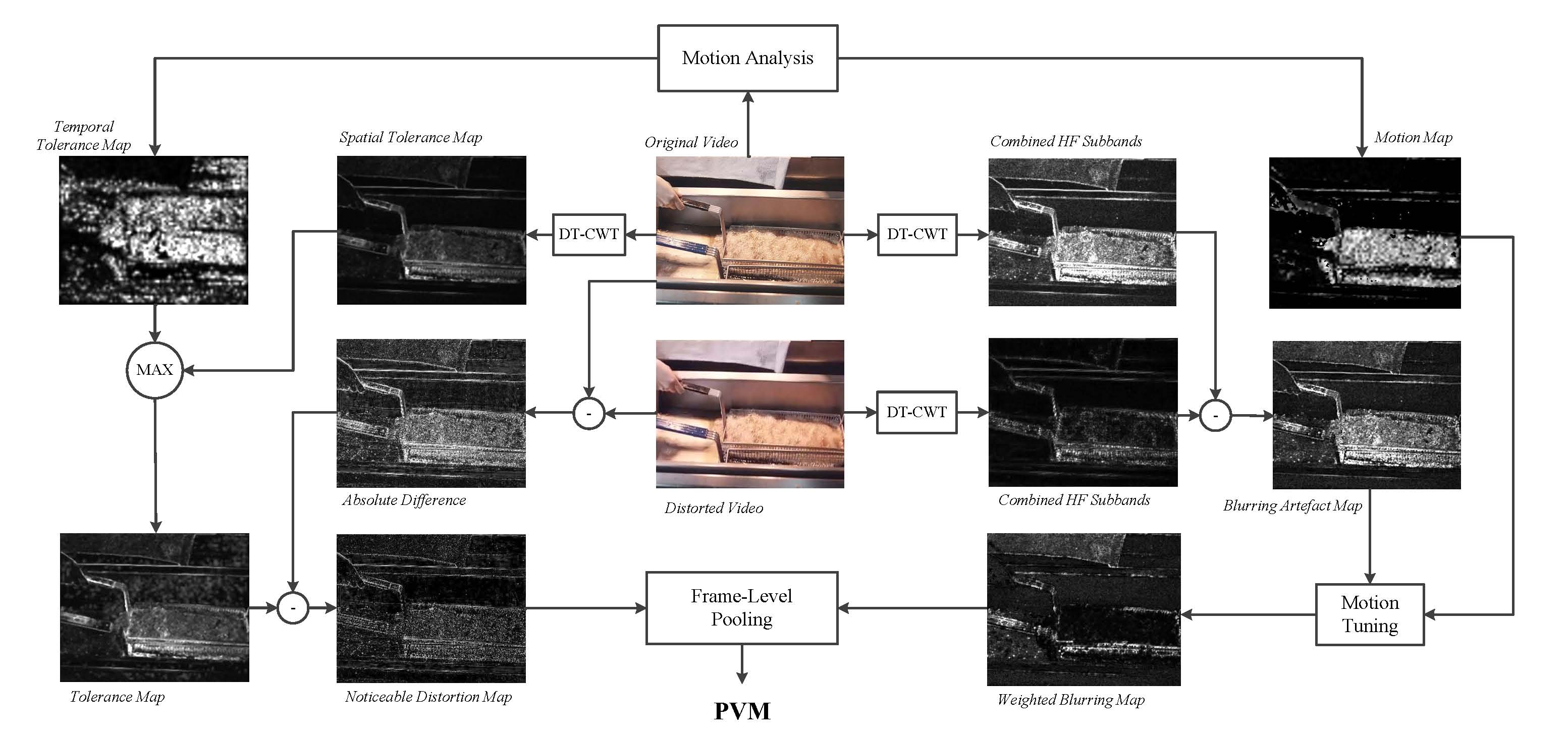
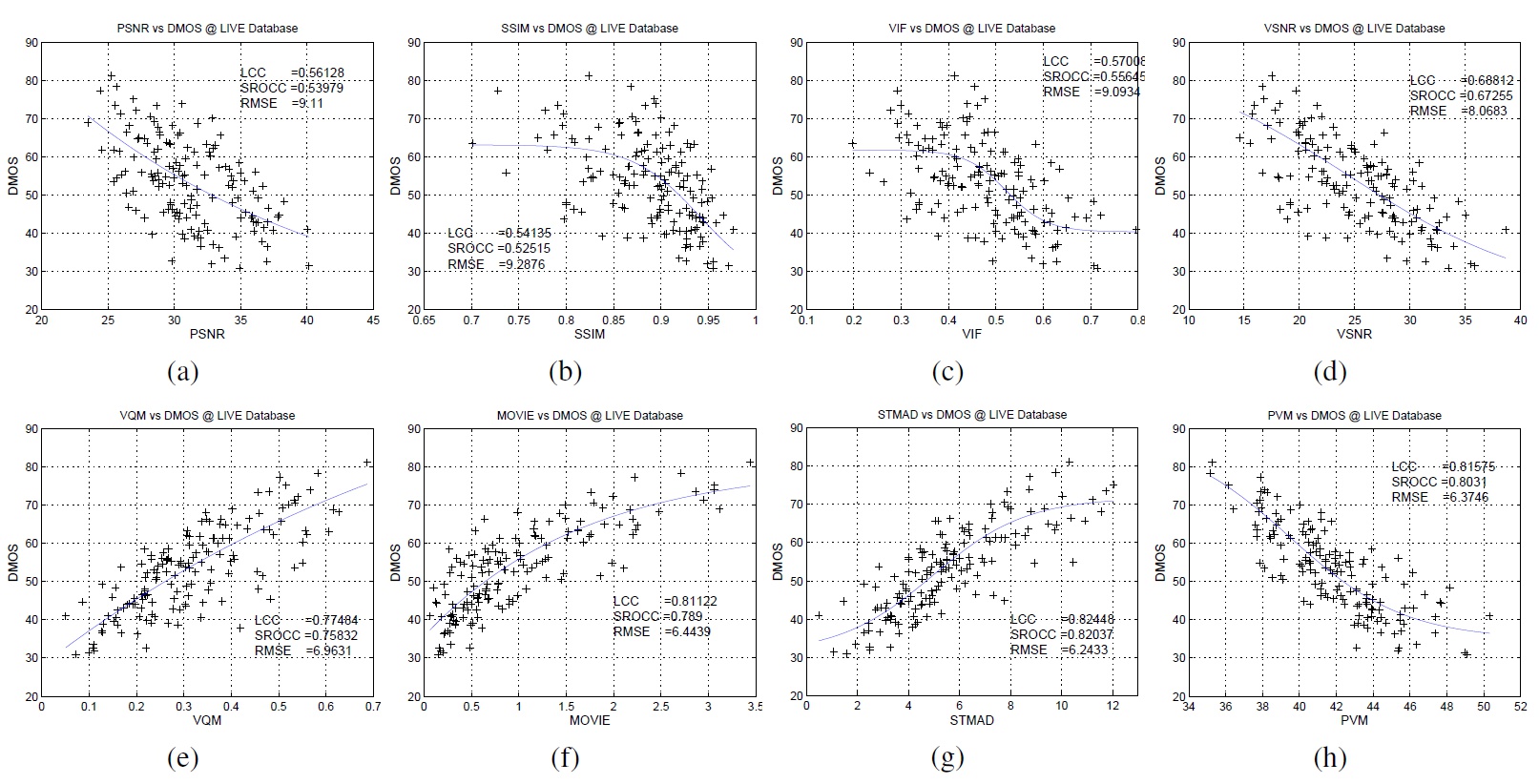
The Group’s relationship with the Communication Systems and Networks Group has produced a body of successful research into the reliable transport of video. The group has proposed a number of error resilient methods which reduce the propagation of errors and conceal, rather than correct them.
Early work (EU FP4 Project “WINHOME”) found that error resilience methods, based on EREC could be combined with adaptive packetisation strategies and data partitioning to provide a robust MPEG-2 transport for in-home TV distribution. WINHOME provided the first European demonstration of robust video transport over WLANs, highlighting the weakness of media-unaware systems and the potential of selective reuse of corrupted packets.
In the EPSRC funded project SCALVID (GR/L43596/01) robust and scalable video coding schemes for heterogeneous communication systems were investigated. In particular the Group investigated a new coding approach based on matching pursuits. SCALVID significantly reduced the complexity of matching pursuits through a hierarchical (primitive operator) correlator structure (patented by NDS) and through the optimisation of basis function dictionaries. This work was widely cited internationally. SCALVID was first to show that matching pursuits can form the basis of an inherently robust coding system.
With BT and JISC funding, JAVIC (Joint Audio Visual Internet Coding) investigated packet-loss-robust internet video coding for multicast applications. Using H.263, reliable streaming with up to 10% packet loss was demonstrated, by combining cross packet FEC, prioritisation and judicious reference frame selection. Following this, the 3CResearch-ROAM4G project, delivered a novel 3-loop Multiple Description Coding scheme which, with minimal redundancy, provides highly robust video transmission over congestion-prone networks (Figure 2). Extended recently to exploit path-diversity in MIMO video systems this has, for the first time, shown that MDC with spatial-multiplexing can deliver up to 8dB PSNR improvement over corresponding SDC systems. ROAM4G also produced a 3D wavelet embedded coder which competes well with MPEG4-SVC and which additionally provides excellent congestion management. Trials are underway with Thales Research.
In the EU FP5 WCAM project (Wireless Cameras and Seamless Audiovisual Networking), the Group in collaboration with Thales Communications (France) and ProVision Communications (UK) produced a wireless H.264 platform incorporating a new spatio-temporal error concealment algorithm, which provides substantial gains (up-to 9dB PSNR improvement over H.264-JM) with up to 20% packet loss (Figure 3). This was singled out by the reviewers and has been patented and successfully licensed. WCAM has also provided an understanding of link adaptation (switching between a range of modulation and FEC schemes according to channel conditions). Realising that throughput based switching metrics are inherently flawed for video, new quality-derived metrics were developed which substantially outperform existing methods.
Work on High Definition coding and transport has progressed further under the Group’s participation in the EU FP5 MEDIANET project where pre- and post-processing algorithms have been developed. Finally, the 3CResearch-project VISUALISE integrated much of the above work into a live-viewing infrastructure where video compression and streaming technology are efficiently deployed over wireless broadband networks in difficult environments. This collaboration between BT Broadcast, Inmarsat, Node, ProVision, U4EA and ISC has developed a way for spectators at large-scale live events to have near real-time access to events as they unfold via portable terminals for an enhanced experience.