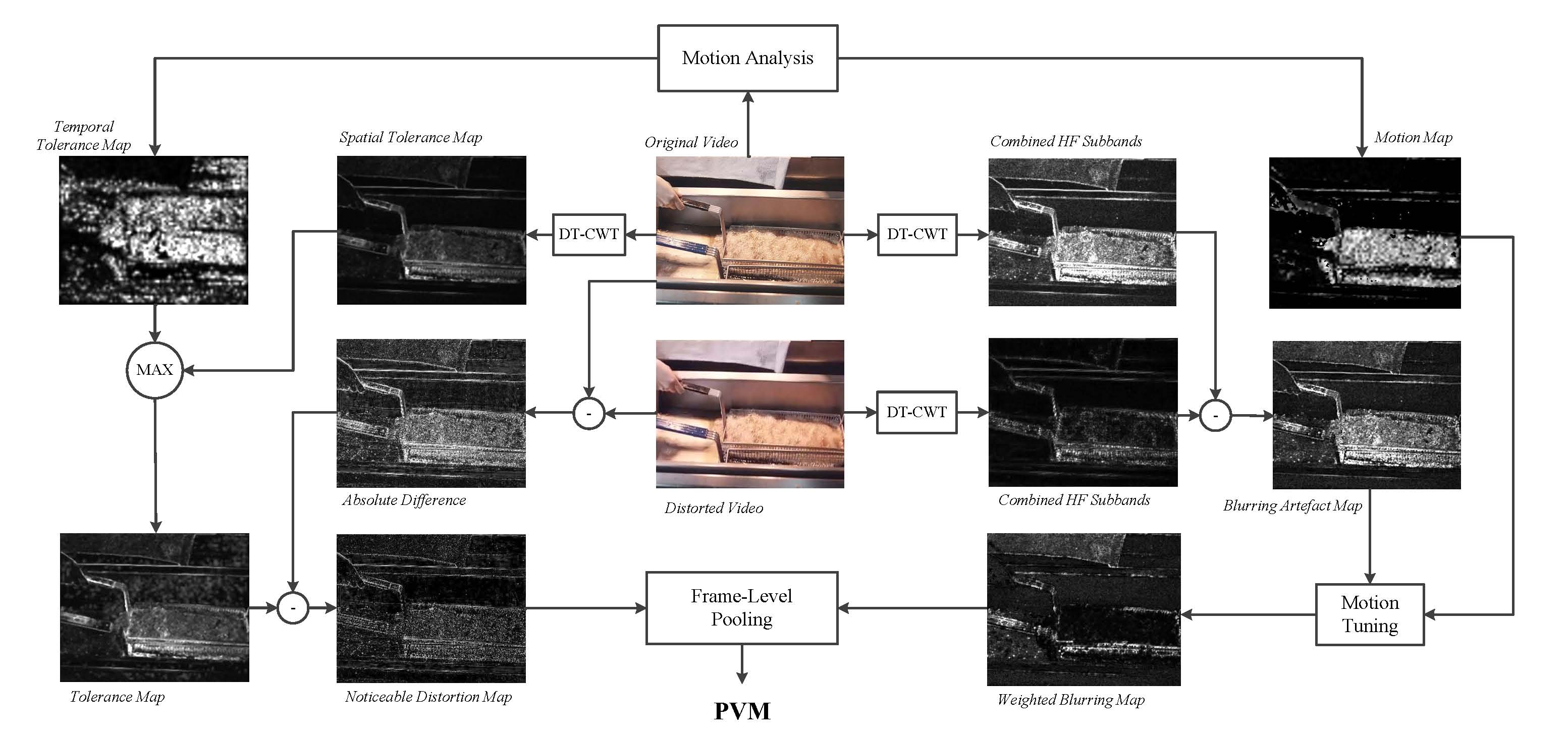
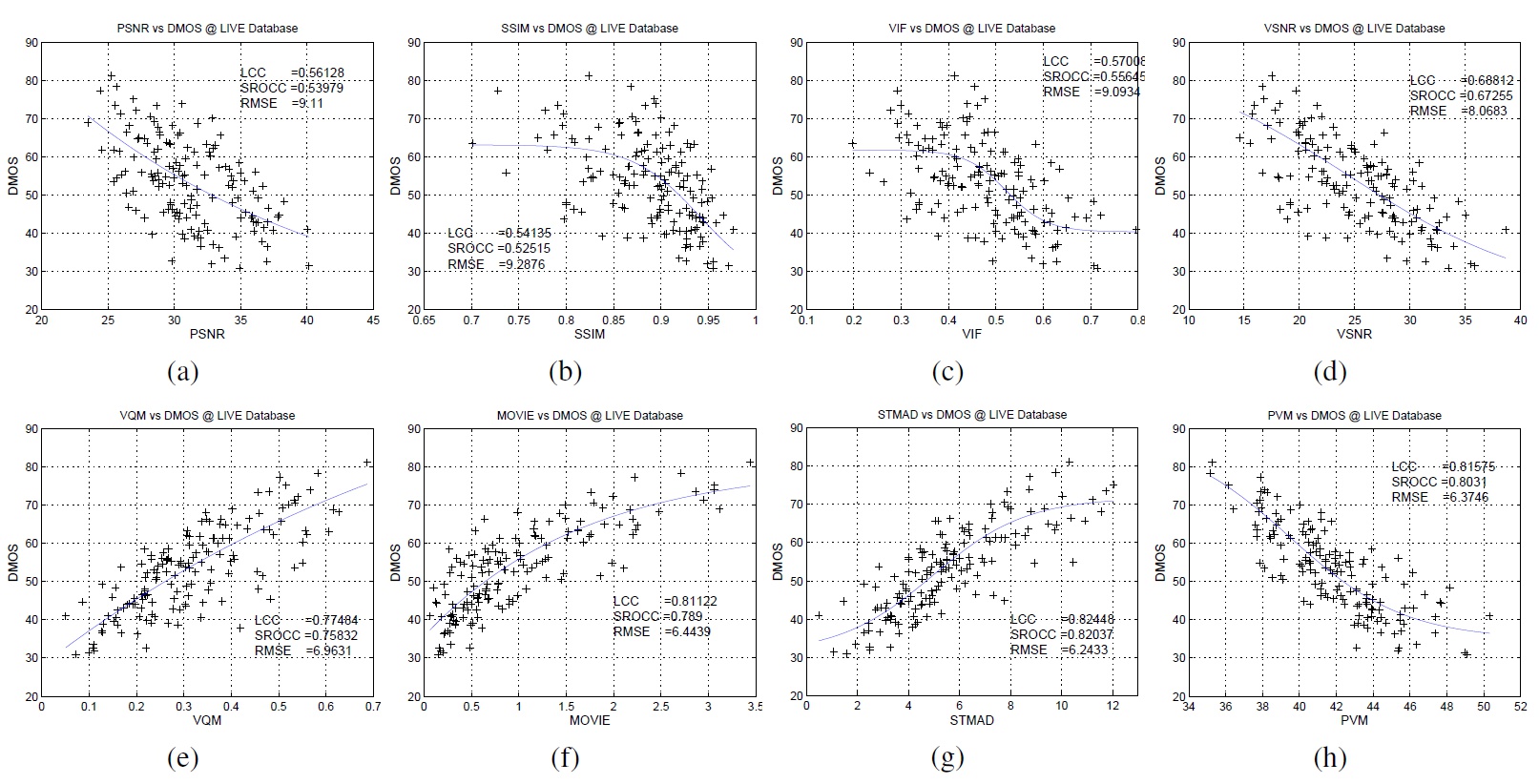
Motion compensated video super-resolution is a technique that uses the sub-pixel shifts between multiple low resolution images of the same scene to create higher resolution frames with improved quality. An important concept is that due to the sub-pixel displacements of picture elements in the low resolution frames, it is possible to obtain high frequency content beyond the Nyquist limit of the sampling equipment. Super-resolution algorithms exploit the fact that as objects move in front of the camera sensor, picture elements captured in the camera pixels might not be visible in the next frame if the movement of the element does not extend to the next pixel. Super-resolution algorithms track and position these additional picture elements in the high-resolution frame. The resulting video quality is significantly improved compared with techniques that only exploit the information in one low-resolution frame to create one high resolution frame.
Super-Resolution techniques can be applied to many areas, including intelligent personal identification, medical imaging, security, surveillance and can be of special interest in applications that demand low-power and low-cost sensors. The key idea is that increasing the pixel size improves the signal to noise ratio and reduces the cost and power of the sensor. Larger pixels enable more light to be collected and in addition the blur introduced by diffraction is reduced. Diffraction is a bigger issue with smaller pixels, so again sensors with larger pixels will perform better, giving sharper images with higher contrast in the fine details, especially in low-light conditions.
Benefits include that increasing the pixel size means that fewer pixels can be located in the sensor and this reduces the sensor resolution. The low-resolution sensor needs to process and transmit a lower amount of information which results in lower power and cost. Super-resolution algorithms running in the receiver side can then be used to recover high-quality and high-resolution videos maintaining a constant frame rate.
Overall, super-resolution enables the system that captures and transmits the video data to be based on low-power and low-cost components while the receiver still obtains a high-quality video stream.
This project has been sponsored by the Centre for Defence Enterprise and DSTL under the Generic Enablers for Low-Size, Weight, Power and Cost (SWAPC) Intelligence, Surveillance, Target Acquisition and Reconnaissance (ISTAR) program.
Click to see some examples :
1: before car number plate in and after super-resolution car number plate SR
2: before vehicles in and after super-resolution vehicles SR
and learn about the theory behind the algorithm: Chen, J, Nunez-Yanez, JL & Achim, A 2014, ‘Bayesian video super-resolution with heavy-tailed prior models’. IEEE Transactions on Circuits and Systems for Video Technology, vol 24., pp. 905-914