Fan Zhang, David Hall, Tao Xu, Stephen Boyle and David Bull
INTRODUCTION
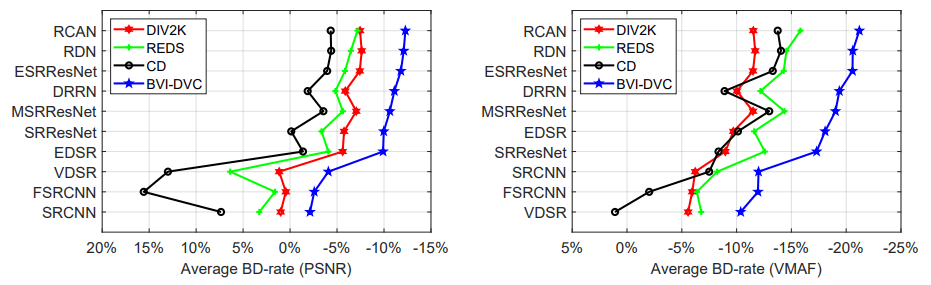
Simulations of drone camera platforms based on actual environments have been identified as being useful for shot planning, training and rehearsal for both single and multiple drone operations. This is particularly relevant for live events, where there is only one opportunity to get it right on the day.
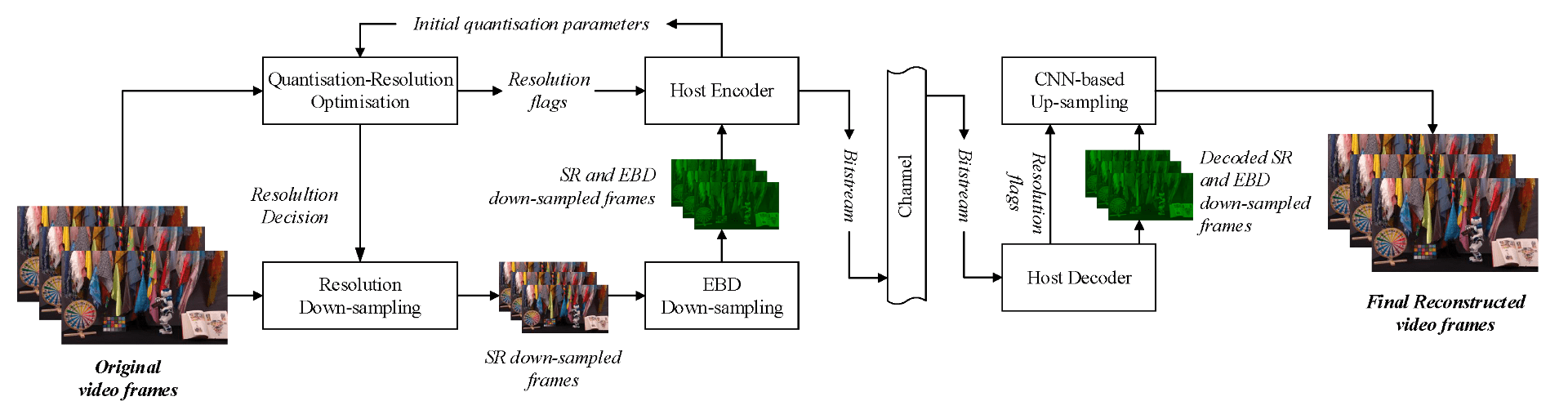
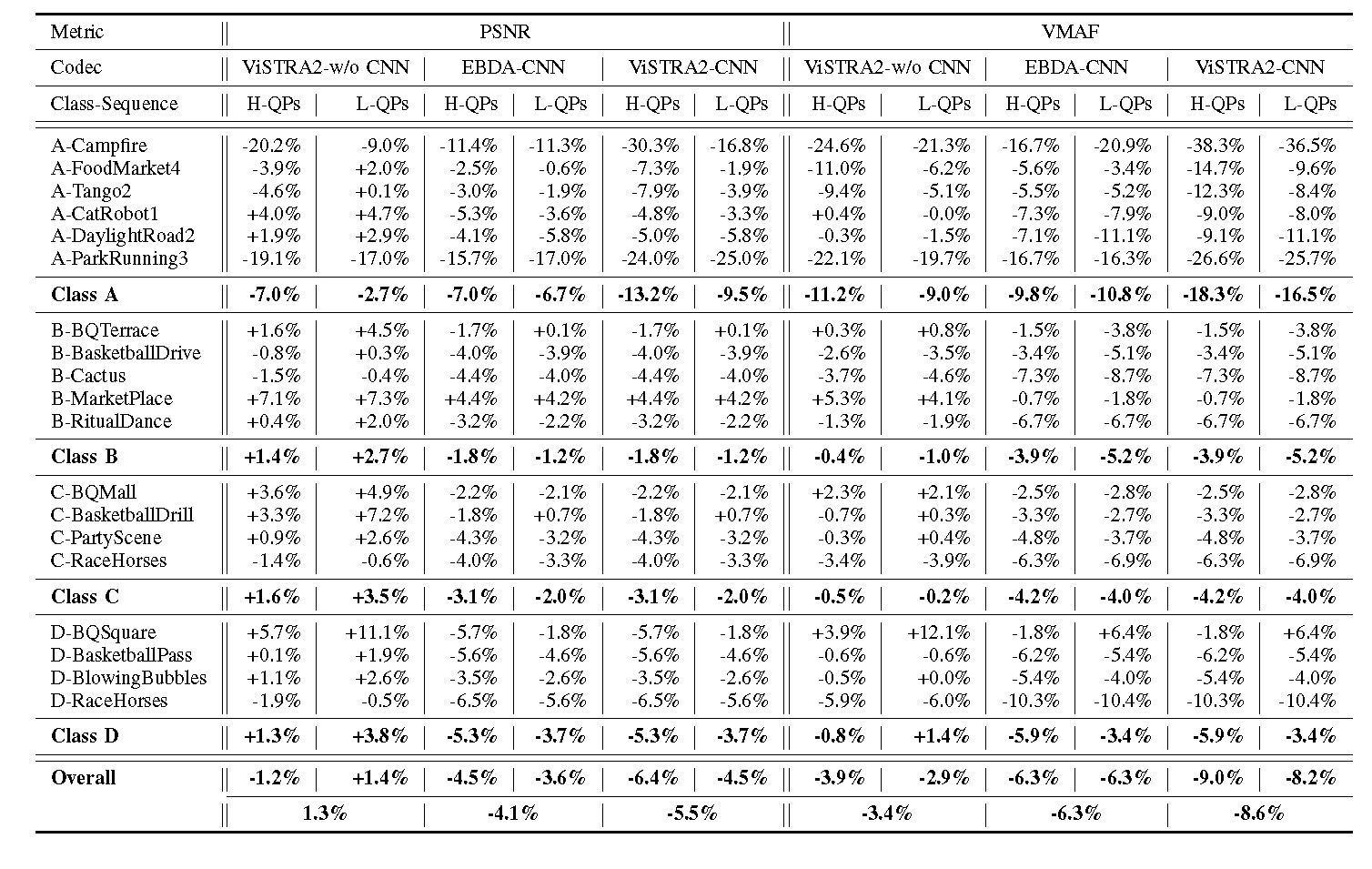
In this context, we present a workflow for the simulation of drone operations exploiting realistic background environments constructed within Unreal Engine 4 (UE4). Methods for environmental image capture, 3D reconstruction (photogrammetry) and the creation of foreground assets are presented along with a flexible and user-friendly simulation interface. Given the geographical location of the selected area and the camera parameters employed, the scanning strategy and its associated flight parameters are first determined for image capture. Source imagery can be extracted from virtual globe software or obtained through aerial photography of the scene (e.g. using drones). The latter case is clearly more time consuming but can provide enhanced detail, particularly where coverage of virtual globe software is limited.
The captured images are then used to generate 3D background environment models employing photogrammetry software. The reconstructed 3D models are then imported into the simulation interface as background environment assets together with appropriate foreground object models as a basis for shot planning and rehearsal. The tool supports both free-flight and parameterisable standard shot types along with programmable scenarios associated with foreground assets and event dynamics. It also supports the exporting of flight plans. Camera shots can also be designed to provide suitable coverage of any landmarks which need to appear in-shot. This simulation tool will contribute to enhanced productivity, improved safety (awareness and mitigations for crowds and buildings), improved confidence of operators and directors and ultimately enhanced quality of viewer experience.
DEMO VIDEOS
REFERENCES
[1] F. Zhang, D. Hall, T. Xu, S. Boyle and D. Bull, “A Simulation environment for drone cinematography”, IBC 2020.
[2] S. Boyle, M. Newton, F. Zhang and D. Bull, “Environment Capture and Simulation for UAV Cinematography Planning and Training”, EUSIPCO, 2019