Di Ma, Fan Zhang and David Bull
INTRODUCTION
Deep learning methods are increasingly being applied in the optimisation of video compression algorithms and can achieve significantly enhanced coding gains, compared to conventional approaches. Such approaches often employ Convolutional Neural Networks (CNNs) which are trained on databases with relatively limited content coverage. In this work, a new extensive and representative video database, BVI-DVC is presented for training CNN-based video compression systems, with specific emphasis on machine learning tools that enhance conventional coding architectures, including spatial resolution and bit depth up-sampling, post-processing and in-loop filtering. BVI-DVC contains 800 sequences at various spatial resolutions from 270p to 2160p and has been evaluated on ten existing network architectures for four different coding tools. Experimental results show that this database produces significant improvements in terms of coding gains over three existing (commonly used) image/video training databases under the same training and evaluation configurations. The overall additional coding improvements by using the proposed database for all tested coding modules and CNN architectures are up to 10.3% based on the assessment of PSNR and 8.1% based on VMAF.
SOURCE EXAMPLES

PERFORMANCE
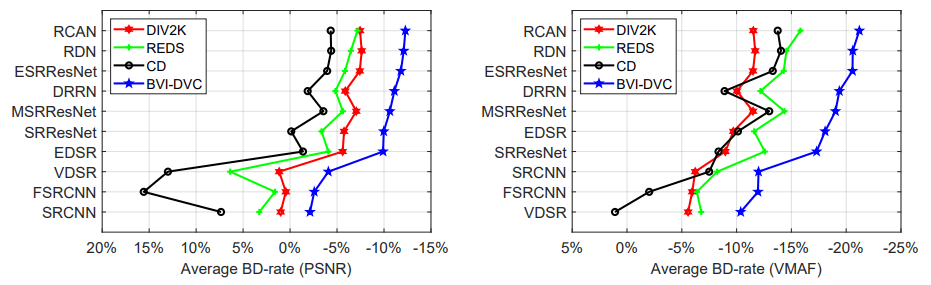
This database has been compared to other three commonly used datasets for training ten popular network architectures which are employed in four different CNN-based coding modules (in the context of HEVC). The figure below shows the average coding gains in terms of BD-rates on JVET test sequences over original HEVC.
USEFUL LINKS
[DOWNLOAD] all videos of this database.
[README] before using the database and for copyright permissions.
If there is any issue regarding this database, please contact fan.zhang@bristol.ac.uk
REFERENCE
If this content has been mentioned in a research publication, please give credit to the University of Bristol, by referencing:
[1] Di Ma, Fan Zhang and David Bull, “BVI-DVC: A Training Database for Deep Video Compression“, arXiv:2003.13552, 2020.
[2] Di Ma, Fan Zhang and David Bull,”BVI-DVC“, 2020.

