Our work is focused on the automatic understanding of object interactions, actions and activities using wearable visual (and depth) sensors. We have addressed novel research questions including assessing action completion, skill/expertise determination from video sequences, discovering task-relevant objects, dual-domain and dual-time learning as well as multi-modal fusion using vision, audio and language.
The group has leads EPIC-KITCHENS, the largest dataset in egocentric vision, with accompanying open challenges. This is associated with the EPIC annual workshop series alongside major conferences (CVPR/ICCV/ECCV).
A selection of our work is described below. You can find further details on Dima’s project research pages.
Datasets: Epic Kitchens
Epic Kitchens is the largest dataset for first-person (egocentric) vision. It contains multi-faceted, audio-visual, non-scripted recordings in native environments – i.e. the wearers’ homes, capturing all daily activities in a kitchen over multiple days.
Further details on all our action recognition data sets and kinks to code can be accessed here.
Understanding semantic similarities

Current video retrieval efforts are based on instance-based assumptions, where only a single caption is relevant to a query video and vice versa. We demonstrate that this assumption results in performance comparisons that are often not indicative of a models’ retrieval capabilities. We propose semantic similarity video retrieval, where (i) multiple videos can be deemed equally relevant, and their relative ranking does not affect a method’s reported performance and (ii) retrieved videos (or captions) are ranked by their similarity to a query.
Further details on publications and code can be found here.
Temporal-relational crosstransformers for action recognition
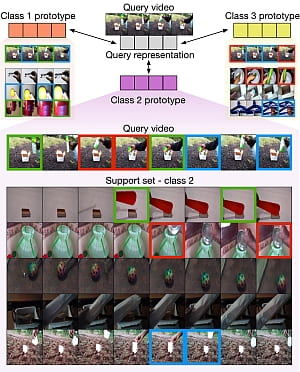
Here we introduce a novel approach to few-shot action recognition, finding temporally-corresponding frame tuples between the query and videos in the support set. Distinct from previous work, we construct class prototypes using the CrossTransformer attention mechanism to observe relevant sub-sequences of all support videos, rather than using class averages or single best matches. Our proposed Temporal-Relational CrossTransformers (TRX) achieve state-of-the-art results on few-shot splits of Kinetics, Something-Something V2 (SSv2), HMDB51 and UCF101.
Further details on publications and code can be found here.
Multi-modal Domain Adaptation for Fine-grained Action Recognition
Fine-grained action recognition datasets exhibit environmental bias, where multiple video sequences are captured from a limited number of environments. Training a model in one environment and deploying in another, often results in performance reduction due to domain shift. Unsupervised Domain Adaptation (UDA) approaches have frequently utilised adversarial training between the source and target domains. In this work we exploit the correspondence of modalities as a self-supervised alignment approach for UDA in addition to adversarial alignment. Using three kitchens from EPIC-Kitchens, using two modalities (RGB and Optical Flow), we show that our approach outperforms source-only training by 2.4% on average. We then combine adversarial training with multi-modal self-supervision, showing that our approach outperforms other UDA methods by 3%.
Further details on publications and code can be found here.
Cross-modal fine-grained action retrieval
We address the problem of cross-modal fine-grained action retrieval between text or audio and video. Cross-modal retrieval is commonly achieved through learning a shared embedding space, that can indifferently embed modalities. Key to our approach is the fact that the visual representation of the textual or audio description is highly dependant on the action to which it applies.
Further details on publications and code can be found here.
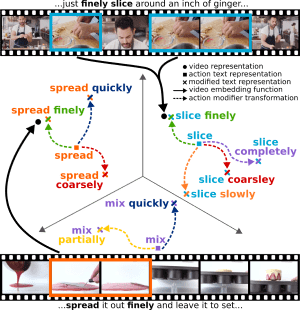
In Action Modifiers: Learning from Adverbs in Instructional Videos we present a method to learn a representation for adverbs from instructional videos using weak supervision from the accompanying narrations. For instance, while ‘spread quickly’ and ‘mix quickly’ will look dissimilar, we can learn a common representation that allows us to recognize both, among other actions. We formulate this as an embedding problem, and use scaled dot-product attention to learn from weakly-supervised video narrations. Our method outperforms all baselines for video-to-adverb retrieval with a performance of 0.719 mAP.
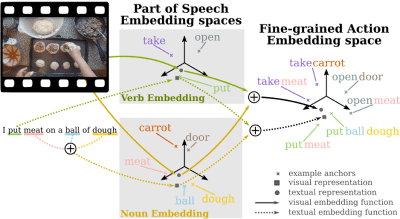
We have also enhanced Fine-Grained Action Retrieval through Multiple Parts-of-Speech Embeddings. Here we enrich embedding by disentangling parts-of-speech (PoS) in the accompanying captions. We build a separate multi-modal embedding space for each PoS tag. The outputs of multiple PoS embeddings are then used as input to an integrated multi-modal space, where we perform action retrieval. Our approach enables learning specialised embedding spaces that offer multiple views of the same embedded entities. Using the EPIC dataset, we show the advantage of our approach for both video-to-text and text-to-video action retrieval.
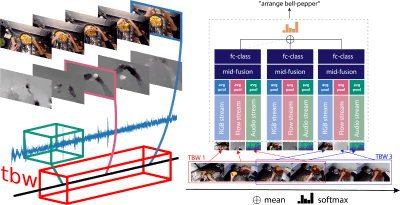
EPIC-Fusion: Audio-Visual Temporal Binding for Egocentric Action Recognition. Here we focus on multi-modal fusion for egocentric action recognition, using a novel architecture for multi-modal temporal-binding (i.e. the combination of modalities within a range of temporal offsets). We train the architecture with three modalities – RGB, Flow and Audio – and combine them with mid-level fusion alongside sparse temporal sampling of fused representations. In contrast with previous work, modalities are fused before temporal aggregation, with shared modality and fusion weights over time. Our approach demonstrates the importance of audio in egocentric vision, on per-class basis, for identifying actions as well as interacting objects and achieves state of the art results on both the seen and unseen test sets of EPIC-Kitchens.